Motivation
- Add a conjugate prior to
θ in pLSA, reduce the number of parameters fromMK+KV toK+KV , which is independent from the number of documents and makes the model less prone to overfitting. - Besides the
β matrix, in pLSA, we learn M points; but in LDA, we learn a dirichlet. So we can easily generalize the trained model to unseen documents.
Specification
original version:

smoothed version:

Parameters for original version:
K : number of topicsM : number of documentsNm : length of m-th documentV : size of vocabularyα : Dirichlet priorβ :K×V , word distribution of topicsθ :M×K , topic distribution of documents
Parameters for smoothed version:
In the orginal version,
Joint distribution:
The marginal distribution of a document:
Posterior distribution of hidden variables:
This posterior is intractable to compute, due to the coupling between
Variational distribution
Here we come up with a variational distribution on latent variables, which can be decomposed as:
and optimize:
to minimize the difference between the variational distribution and the true posterior distribution.
Play with the formula above and we will get:
where
So minimizing the KL divergence is equivalent to maximizing the function
Parameter estimation
Variational EM algorithm:
- E-step: maximize the lower bound
L(γ,ϕ;α,β) with respect to the variational parametersγ andϕ - M-step: maximize the bound with respect to the model parameters
α andβ
E-step: variational inference
A few more steps:
Struggle through heavy math to compute each term and we finally get (
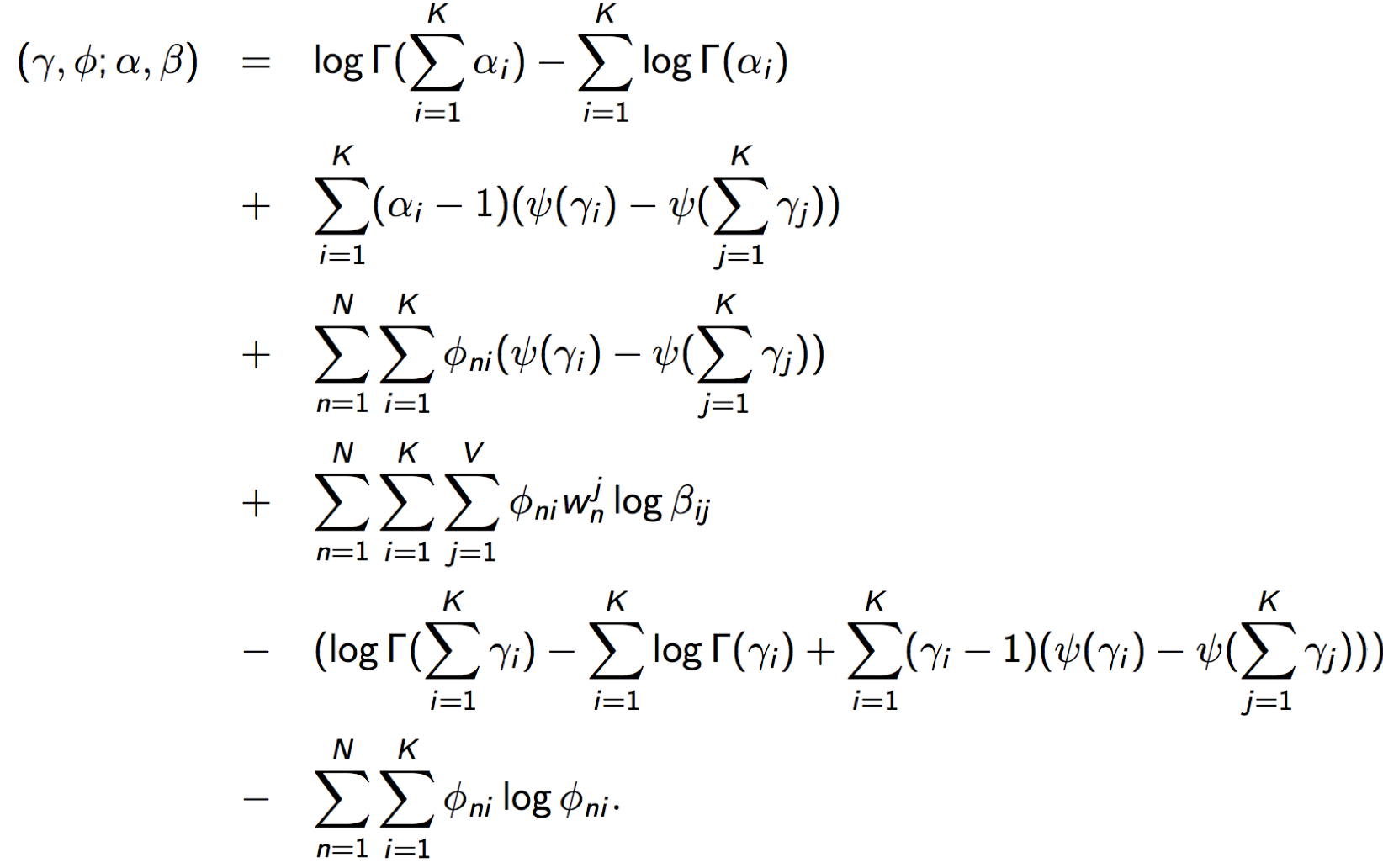
Taking derivatives of this function and set derivatives to zero yields the update formulas.
The variational inference algorithm update

M-step
Maximize
Taking the derivative with respect to
Maximize
Taking the derivative with respect to
It is difficult to compute
and input this Hessian Matrix and the derivative to Newton Method to get
Gibbs Sampling
(for smoothed version)
Theoretical analysis:
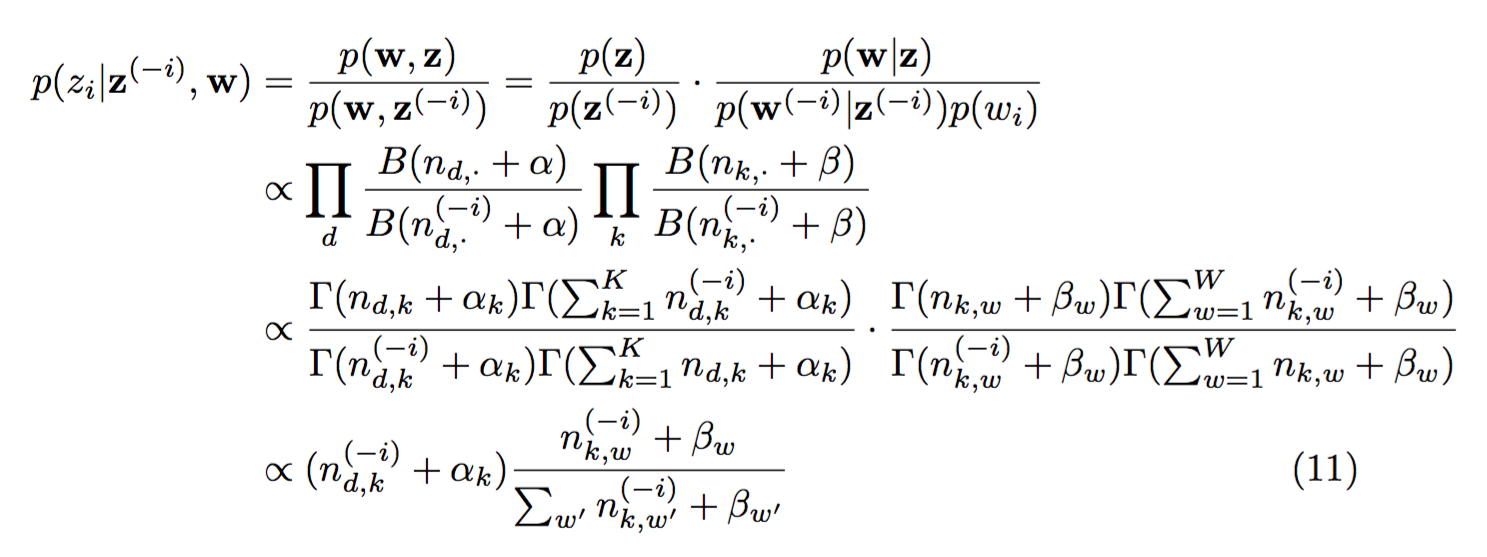
due to conjugate prior. Note that the normalizer of the first term is omitted, because the sum is the length of each document, which is fixed, while the second denominator might change after each update.
Algorithm:

Comparisons and discussions for MCMC and Variational Bayes see Variational Bayes.
Extensions
Relaxing the assumptions:
- order of words doesn't matter ("Bag of words" assumption)
- order of documents doesn't matter => time-evolving, dynamic topic model
- the number of topics is assumed known, fixed and flat => Bayesian nonparametric topic model
- topics are not correlated => correlated topic model
- ...
incorporating meta-data:
authors, links, other labels(supervised)...
other problems
model checking, visualization, data discovery...
References
Blei, David M. "Probabilistic topic models." Communications of the ACM 55.4 (2012): 77-84.
"Machine Learning" Lecture 19: http://www.umiacs.umd.edu/~jbg/teaching/CSCI_5622/
"Probabilistic Models for Unsupervised Learning" Lecture 5: http://home.cse.ust.hk/~lzhang/teach/6931a/
Dirichlet-Multinomial Distribution: https://en.wikipedia.org/wiki/Dirichlet-multinomial_distribution#A_combined_example:_LDA_topic_models
Darling, William M. "A theoretical and practical implementation tutorial on topic modeling and gibbs sampling." Proceedings of the 49th annual meeting of the association for computational linguistics: Human language technologies. 2011.